|
|
|
@@ -7,7 +7,7 @@ draft: false |
|
|
|
I wanted to get back into ARM assembler so I wrote my own strlen. And then I looked at the strlen() glibc uses and did not understand |
|
|
|
a single thing. So I sat down and figured it out. |
|
|
|
|
|
|
|
XXX IMG HERE XXX |
|
|
|
 |
|
|
|
|
|
|
|
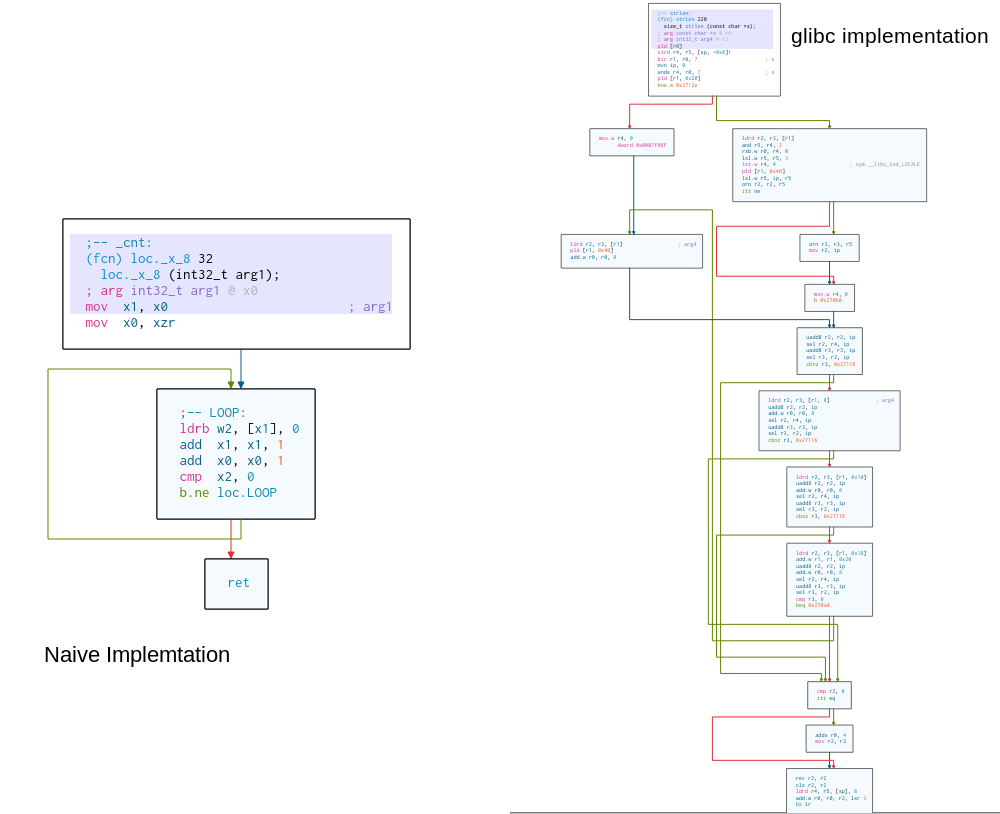
On the left you see a flow diagram of the building blocks of my naive implementation. On the right you see glibc's. You might |
|
|
|
notice that it is more complex. (How much faster it is, and which optimization exactly makes it fast is an interesting topic. |
|
|
|
@@ -22,7 +22,7 @@ The first thing I noticed about the inner loop is that it is unrolled. That is a |
|
|
|
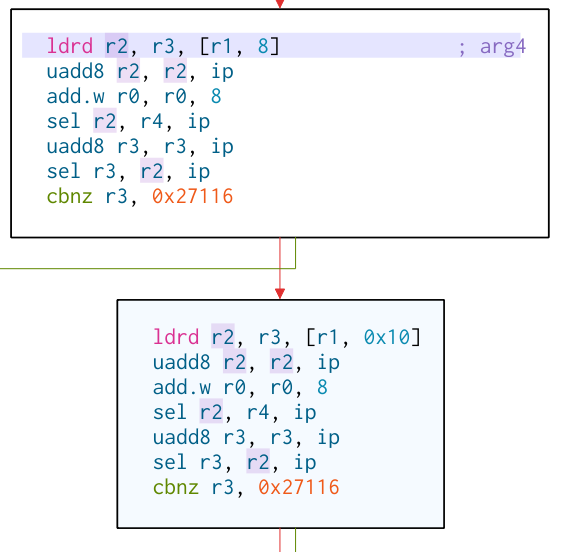
because strlen does not clearly unroll as the input is cleanly divisible by word size. So on the end of every basic block there |
|
|
|
is a check which skips out of the loop and to the end where the result is calculated and returned. |
|
|
|
|
|
|
|
XXX IMG HERE XXX |
|
|
|
 |
|
|
|
|
|
|
|
The basic blocks are basically identical. First the registers r2 and r3 are populated with the next two words to be checked for |
|
|
|
the null byte. Now r2 and r3 each contain one word (i.e. 4 bytes). How do you check whether there is a null byte *somewhere* in them? |


{kind=link}
{kind=link}